Reading a Comma Delimited File in Python
Intro: In this article, I volition walk y'all through the different means of reading and writing CSV files in Python.
Tabular array of Contents:
- What is a CSV?
- Reading a CSV
- Writing to a CSV
i. What is a CSV?
CSV stands for "Comma Separated Values." Information technology is the simplest form of storing data in tabular form every bit plain text. It is important to know to work with CSV because we by and large rely on CSV data in our day-to-day lives as data scientists.
Structure of CSV:

We accept a file named "Salary_Data.csv." The first line of a CSV file is the header and contains the names of the fields/features.
After the header, each line of the file is an observation/a record. The values of a record are separated past "comma."
2. Reading a CSV
CSV files tin can be handled in multiple ways in Python.
two.1 Using csv.reader
Reading a CSV using Python's inbuilt module chosen csv using csv.reader object.
Steps to read a CSV file:
1. Import the csv library
import csv
2. Open the CSV file
The .open up() method in python is used to open files and return a file object.
file = open('Salary_Data.csv') type(file) The type of file is "_io.TextIOWrapper" which is a file object that is returned by the open() method.
3. Utilise the csv.reader object to read the CSV file
csvreader = csv.reader(file)
4. Extract the field names
Create an empty list called header. Employ the next() method to obtain the header.
The .next() method returns the current row and moves to the adjacent row.
The first fourth dimension you run next() information technology returns the header and the adjacent fourth dimension you run information technology returns the first record and so on.
header = [] header = side by side(csvreader) header

five. Extract the rows/records
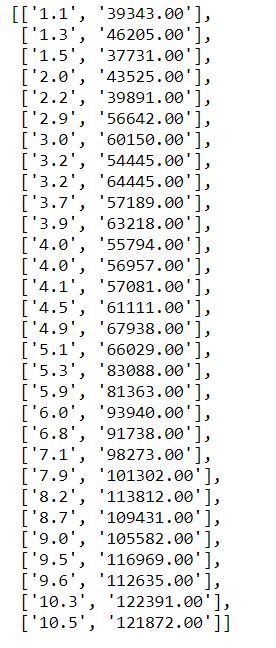
Create an empty listing called rows and iterate through the csvreader object and append each row to the rows listing.
rows = [] for row in csvreader: rows.suspend(row) rows
6. Close the file
.close() method is used to close the opened file. Once it is closed, nosotros cannot perform whatever operations on it.
file.shut()
Consummate Code:
import csv file = open up("Salary_Data.csv") csvreader = csv.reader(file) header = next(csvreader) print(header) rows = [] for row in csvreader: rows.append(row) print(rows) file.close() Naturally, we might forget to close an open file. To avert that nosotros tin can use the with()statement to automatically release the resources. In simple terms, there is no need to phone call the .shut() method if we are using with() argument.
Implementing the higher up code using with() argument:
Syntax: with open(filename, mode) as alias_filename:
Modes:
'r' – to read an existing file,
'w' – to create a new file if the given file doesn't exist and write to it,
'a' – to append to existing file content,
'+' – to create a new file for reading and writing
import csv rows = [] with open("Salary_Data.csv", 'r) as file: csvreader = csv.reader(file) header = adjacent(csvreader) for row in csvreader: rows.append(row) impress(header) print(rows) 
2.two Using .readlines()
Now the question is – "Is it possible to fetch the header, rows using only open up() and with() statements and without the csv library?" Let'southward see…
.readlines() method is the respond. It returns all the lines in a file equally a listing. Each item of the list is a row of our CSV file.
The beginning row of the file.readlines() is the header and the balance of them are the records.
with open('Salary_Data.csv') as file: content = file.readlines() header = content[:1] rows = content[1:] impress(header) print(rows) 
**The 'n' from the output tin be removed using .strip() method.
What if we take a huge dataset with hundreds of features and thousands of records. Would it be possible to handle lists??
Here comes the pandas library into the picture.
2.3 Using pandas
Steps of reading CSV files using pandas
1. Import pandas library
import pandas as pd
2. Load CSV files to pandas using read_csv()
Basic Syntax: pandas.read_csv(filename, delimiter=',')
information= pd.read_csv("Salary_Data.csv") data 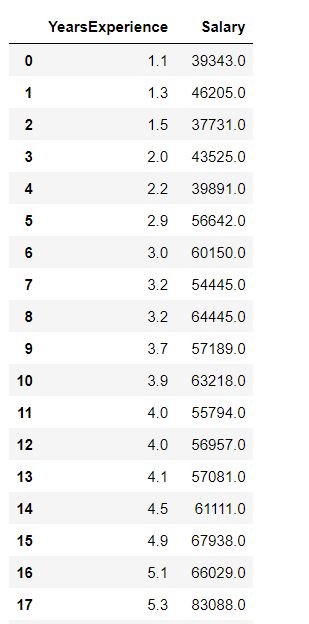
iii. Excerpt the field names
.columns is used to obtain the header/field names.
data.columns

4. Excerpt the rows
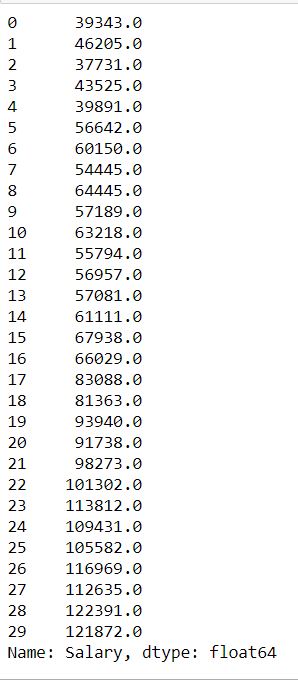
All the information of a data frame can be accessed using the field names.
data.Salary
iii. Writing to a CSV file
We can write to a CSV file in multiple ways.
iii.1 Using csv.writer
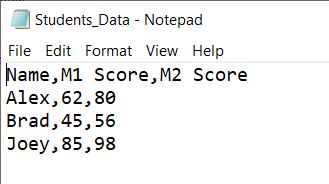
Let'due south presume we are recording 3 Students data(Name, M1 Score, M2 Score)
header = ['Proper noun', 'M1 Score', 'M2 Score'] data = [['Alex', 62, 80], ['Brad', 45, 56], ['Joey', 85, 98]]
Steps of writing to a CSV file:
ane. Import csv library
import csv
2. Define a filename and Open the file using open()
3. Create a csvwriter object using csv.writer()
4. Write the header
5. Write the rest of the information
code for steps 2-5
filename = 'Students_Data.csv' with open up(filename, 'w', newline="") as file: csvwriter = csv.writer(file) # 2. create a csvwriter object csvwriter.writerow(header) # 4. write the header csvwriter.writerows(data) # 5. write the rest of the data
Below is how our CSV file looks.
3.2 Using .writelines()
Iterate through each list and convert the list elements to a string and write to the csv file.
header = ['Name', 'M1 Score', 'M2 Score'] information = [['Alex', 62, lxxx], ['Brad', 45, 56], ['Joey', 85, 98]] filename = 'Student_scores.csv' with open(filename, 'west') as file: for header in header: file.write(str(header)+', ') file.write('n') for row in information: for x in row: file.write(str(ten)+', ') file.write('n') 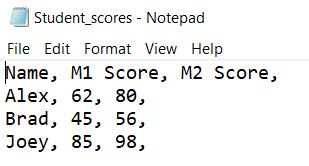
3.iii. Using pandas
Steps to writing to a CSV using pandas
1. Import pandas library
import pandas as pd
2. Create a pandas dataframe using pd.DataFrame
Syntax: pd.DataFrame(information, columns)
The data parameter takes the records/observations and the columns parameter takes the columns/field names.
header = ['Name', 'M1 Score', 'M2 Score'] information = [['Alex', 62, 80], ['Brad', 45, 56], ['Joey', 85, 98]] data = pd.DataFrame(data, columns=header)
three. Write to a CSV file using to_csv()
Syntax: DataFrame.to_csv(filename, sep=',', index=Fake)
**separator is ',' past default.
index=False to remove the index numbers.
information.to_csv('Stu_data.csv', alphabetize=Faux) Below is how our CSV looks like

End Notes:
Cheers for reading till the decision. Past the end of this article, we are familiar with unlike ways of handling CSV files in Python.
I hope this commodity is informative. Feel free to share information technology with your study buddies.
References:
Check out the complete code from the GitHub repo.
Other Blog Posts by me
Feel gratis to cheque out my other weblog posts from my Analytics Vidhya Profile.
You lot can notice me on LinkedIn, Twitter in instance you would want to connect. I would be glad to connect with you.
For immediate exchange of thoughts, please write to me at harikabont[email protected].
Source: https://www.analyticsvidhya.com/blog/2021/08/python-tutorial-working-with-csv-file-for-data-science/
{kind=link}
Post a Comment for "Reading a Comma Delimited File in Python"